Starcraft 2 Reinforcement Learning
November 28, 2022 2:28 PMStarcraft 2 RL
Introduction
Starcraft 2 is a very complicated strategic video game, but it’s number of possible play combinations exceeds games like Chess by millions of times. There is no single way to play and no single good strategy to win a game. This is why, in such a difficult game we would want to create an agent that is able to exceed a human player and win. A simple bot would not be enough, because, even taking into account a limited amount of strategies, the code base would become immense just in a couple of play moves, so a RL agent would be more efficient and would in the end give us better results for a variety of situations, taking into account the adaptability to new situations.
One solution to this is a Reinforcement Learning agent, that would be able to choose what would be the best action, given the current situation. But this would also take a lot of time to master and train properly, being difficult to reward the agent when there are a large amount of single actions that it can take at a certain time.
A way to facilitate this process would be to program a finite number of well defined strategies (”actions”) that out agent can pick from, being rewarded from the outcome of those situations accordingly.
In order for us to to train a reinforcement learning agent, we need to understand the structure of the video game, what data can we extract and use as inputs and what would be the rewards.
Input data
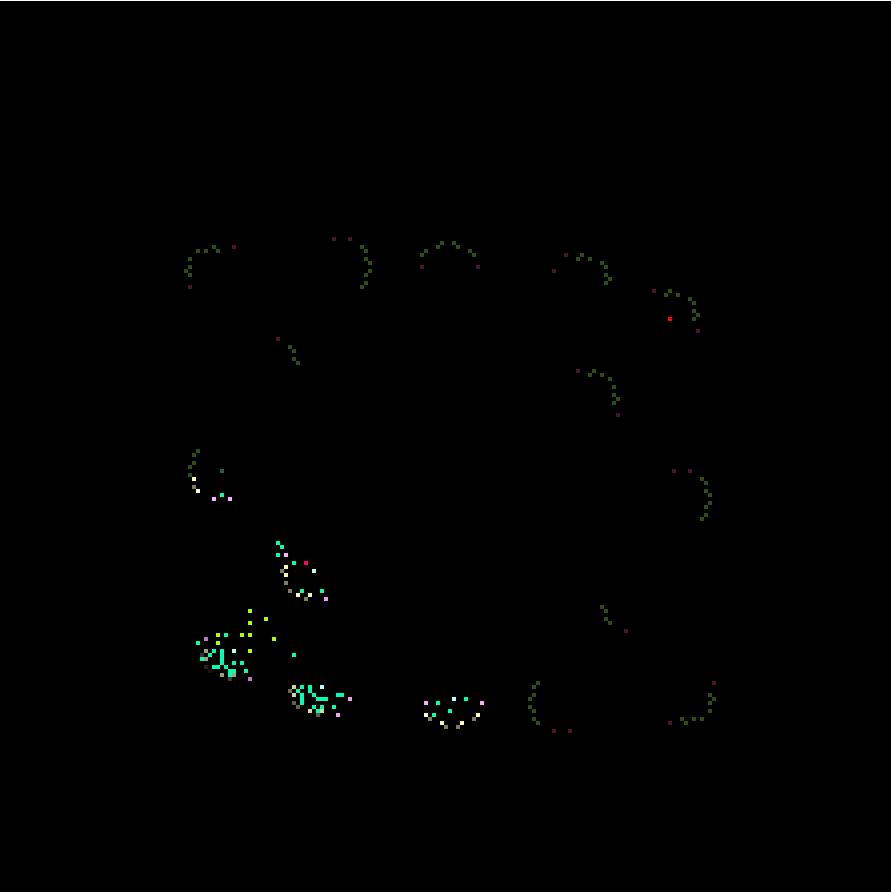
Reconstructed map as a matrix
In-game mini-map
One the best ways to represent data in this case is visually, making use of the in game map and the information provided by the bot API. We can construct a matrix that has the same size as the game map and draw known information on top of it.
We represent such data in the form of colored pixels:
- Friendly: Units, Structures, Vespine geysers
- Enemy: Start location, Units, Structures
- Environment: Minerals
Pixel brightness is one of the factors that helps us keep track of “amount” and feed to the agent. This “amount” factor is present in multiple parameters, such as the representation of the resources left in each mineral square, the HP of units and structures. It also represents the unknown data, the dim level of resources will represent the minerals that we did not manage to see yet.
Actions
There are 2 main types of actions that a SC2 bot can perform: Micro and Macro actions.
For the agent actions we are going to focus on the Macro actions, as the micro actions require a more complicated data representation, more training and a better reward system, or another model running in parallel just for the small tasks like building optimization, evaluate fight outcomes and enemy control (kite, retreat, individual unit abilities and more).
Macro actions refers to the important and impactful actions that a bot can make. This means broad decisions that are used to decide the main performed action.
The actions are as follows:
Expand:
- Expand to a new location (build a new nexus)
- Create worker units (Probes)
- Build Pylons, so we can expand with new structures
- Start exploiting the available minerals
- Build assimilators on the closest Vespine Geysers
Build:
- Build structures that are needed in order to produce desired units
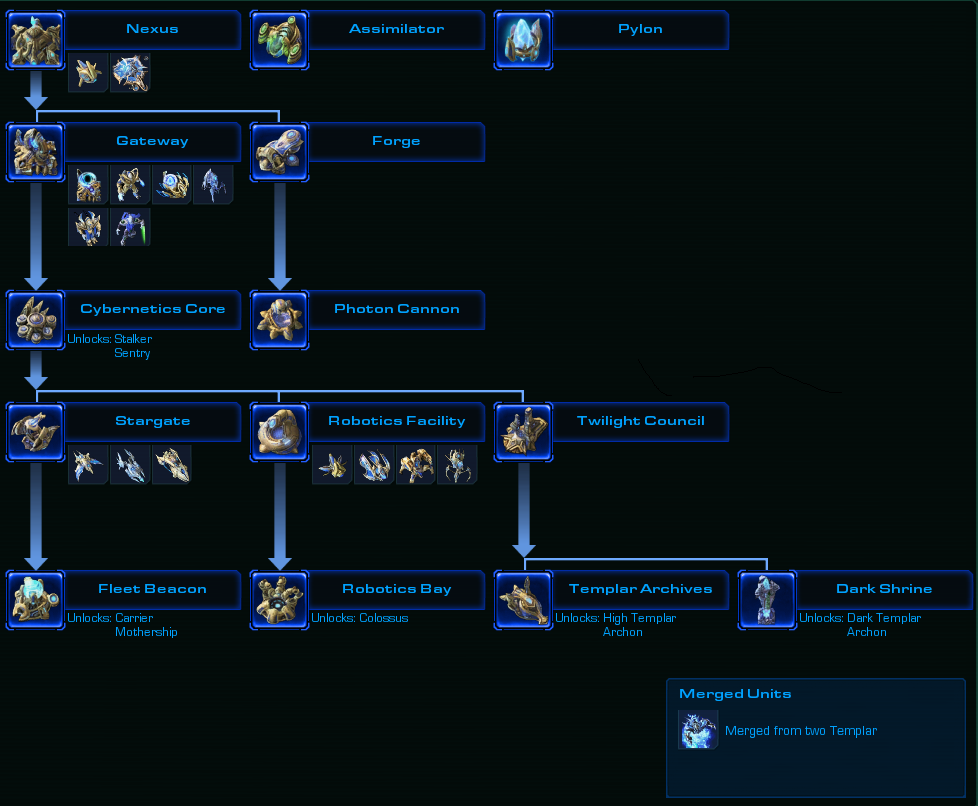
Structure tree for Protos
Recruit:
- Check if it can afford certain types of units
- Recruit units
Scout:
- Account for the enemy scouts
- Send a dummy probe to the enemy location
Attack:
- Gather all units (or a certain formation)
- Attack known enemy units
- Attack known enemy structures
- Seek the enemy at the known start location
- Execute known attack strategies (if there are any)
Retreat:
- Return the unit to base location (start location)
The set of actions can be customizable to fit a certain strategy, such as recruiting certain groups of specific units before launching an attack, or a pre-defined build order for structures, this can also include defensive structure placement.
Reward
Because of the complexity of our problem (can be thousands of action combinations in each game), we can not simply reward the agent for just winning and losing games, we have to be way more specific and insert smaller intermediary rewards.
Usually, when designing a RL system, the reward assignment is the hardest to deal with. We could incentivize the agent to do certain actions that usually lead to wins, like amount of time the agent’s units are engaged in combat, how much scouted area does he have, how many resources does he not spend ,and many more.
In this case we will try different combinations of rewards and reward amounts in order to determine which one will give the best results.
Algorithms
For out training we will use a custom Stable Baselines 3 environment. There are many algorithms for training a good agent, but we would like to focus on 2 of the most used and popular: PPO (Proximal Policy Optimization) and A2C (Advantage Actor Critic), and compare the results.
PPO:
It is one of the most popular approaches to RL and it presents better results than state-of-the-art works, while managing to keep it’s complexity low. It has become the go-to RL algorithm at OpenAI, being used for RL in robotics and video games.
It has an attention function that helps estimating how good a certain action is compared to an average action for a specific state, by that, it manages to reduce the considerable variation between the old policy and the new policy.
A2C:
It combines 2 fundamental RL algorithms: Policy Based and Value Based, resulting in a hybrid architecture, where the 2 algorithms help stabilize the training, being able to reduce variance.
The Actor in this case controls how our agent behaves, what action is he taking, and the Critic measures how good where the previously performed actions.
Technologies
Stable baselines
- The most popular RL gym framework is called Stable Baselines,
- Stable Baselines3 (SB3) is a set of reliable implementations of reinforcement learning algorithms in PyTorch.
- RL Baselines3 Zoo is a training framework for Reinforcement Learning (RL).
- It provides scripts for training, evaluating agents, tuning hyperparameters, plotting results and recording videos.
Setup and run process
Use a train.py file in order to run and start all the necessary things for the training process, which is basically a stable baselines3 script that also runs the SC2 environment file for the custom training environment. In there, we define the Action and Observation space for the agent. Before training we enter the reset state and empty the map, preparing the pickle file containing the state of the game, than we run the game in another process in parallel.
We get an observation through the reset method mentioned earlier and that passes on to the model that we choose (PPO or A2C model). That model is able to choose an action from the action pool. Afterwards, the action is passed to the step method of our env, which is perpetually waiting for an action to be picked by the model, the action is passed to the state dictionary.
Our bot.py script detects the action performs it in the actual game, redrawing the map with all it’s components, calculating the rewards and re-sending it to the environment, and the cycle goes on.